
【MySQL】Covering Index で処理が高速化するのを確認する
問題
Covering Index って何ですか。

答え
Covering index
Covering index は索引中にキーではない列を含める方式である。もし索引を使う検索が、行全体ではなく、キーと幾つかの列のみを必要とする場合、その必要とされる列が索引のデータ構造内にあれば、検索は索引内で完結できる。表からデータを読み取る必要が無いため効率が良い。
Covering index は表のサイズがメモリに保持しきれないほど大きい場合の検索で有効であるが、索引のサイズは増加することに注意が必要である。また、キーでない列の値が変更された際にも索引を更新する必要があるため、更新の性能は低下する傾向がある。
では、MySQL5.5 InnoDBのテーブルにて実験する。
実験の準備
こんなテーブルを用意する。
mysql> create table item (
-> item_id int primary key auto_increment,
-> item_type int,
-> item_price int,
-> item_data1 text,
-> item_data2 text,
-> item_data3 text
-> );
データを追加する。
(とりあえず5種類作って) mysql> insert into item (item_type, item_price) values (1, 100); mysql> insert into item (item_type, item_price) values (2, 200); mysql> insert into item (item_type, item_price) values (3, 300); mysql> insert into item (item_type, item_price) values (4, 400); mysql> insert into item (item_type, item_price) values (5, 500); (20回ぐらい倍々してレコード数を増やす) mysql> insert into item (item_type, item_price) select item_type, item_price from item; mysql> insert into item (item_type, item_price) select item_type, item_price from item; mysql> insert into item (item_type, item_price) select item_type, item_price from item; ... ... mysql> insert into item (item_type, item_price) select item_type, item_price from item; (実験用データが500万行できているのを確認) mysql> select count(*) from item; +----------+ | count(*) | +----------+ | 5242880 | +----------+
下ごしらえ、以上。
実験
インデックスも何もなしで、item_type ごとの item_price の合計を出してみる。
mysql> select item_type, sum(item_price) from item group by item_type; +-----------+-----------------+ | item_type | sum(item_price) | +-----------+-----------------+ | 1 | 104857600 | | 2 | 209715200 | | 3 | 314572800 | | 4 | 419430400 | | 5 | 524288000 | +-----------+-----------------+ 5 rows in set (3.36 sec)
高速化するには item_type でインデックスを作成するとよいのではないかということで、インデックス作成。
mysql> alter table item add index (item_type);
mysql> select item_type, sum(item_price) from item group by item_type; +-----------+-----------------+ | item_type | sum(item_price) | +-----------+-----------------+ | 1 | 104857600 | | 2 | 209715200 | | 3 | 314572800 | | 4 | 419430400 | | 5 | 524288000 | +-----------+-----------------+ 5 rows in set (1 min 7.66 sec)
あ、あれ?
mysql> explain select item_type, sum(item_price) from item group by item_type; +----+-------------+-------+-------+---------------+-----------+---------+------+---------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+-----------+---------+------+---------+-------+ | 1 | SIMPLE | item | index | NULL | item_type | 5 | NULL | 5243155 | | +----+-------------+-------+-------+---------------+-----------+---------+------+---------+-------+
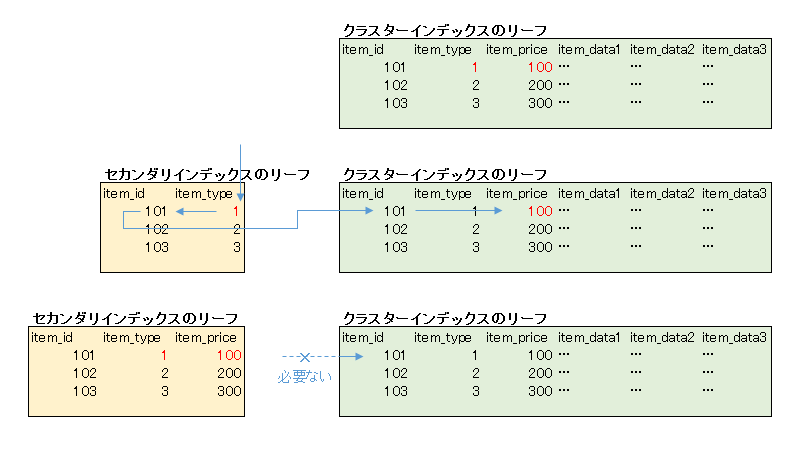
この状況で主キー以外のインデックスを使うと、インデックスを使って目的のレコードの主キーを取得して、そのレコードのデータ(ここでは item_price)を主キーで取りに行くという動きをするようで、ディスクI/Oがとても激しくなる。それなら下手にインデックスを使わないで、上から下までスキャンした方が速かったということらしい。
ではここで、item_typeだけでなくitem_priceも含めたインデックスを作ってみるとどうなるか。
mysql> alter table item add index (item_type, item_price);
同じように集計を実行すると
mysql> select item_type, sum(item_price) from item group by item_type; +-----------+-----------------+ | item_type | sum(item_price) | +-----------+-----------------+ | 1 | 104857600 | | 2 | 209715200 | | 3 | 314572800 | | 4 | 419430400 | | 5 | 524288000 | +-----------+-----------------+ 5 rows in set (1.59 sec)
速くなった!最初のインデックスなしよりも速くなった!
これは、item_price も含めたインデックスを作ることで、インデックスのリーフだけで item_price が分かるので、主キーでレコード全体を探しに行く必要がなくなり、高速化したということのようです。
コメント